RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Descrição
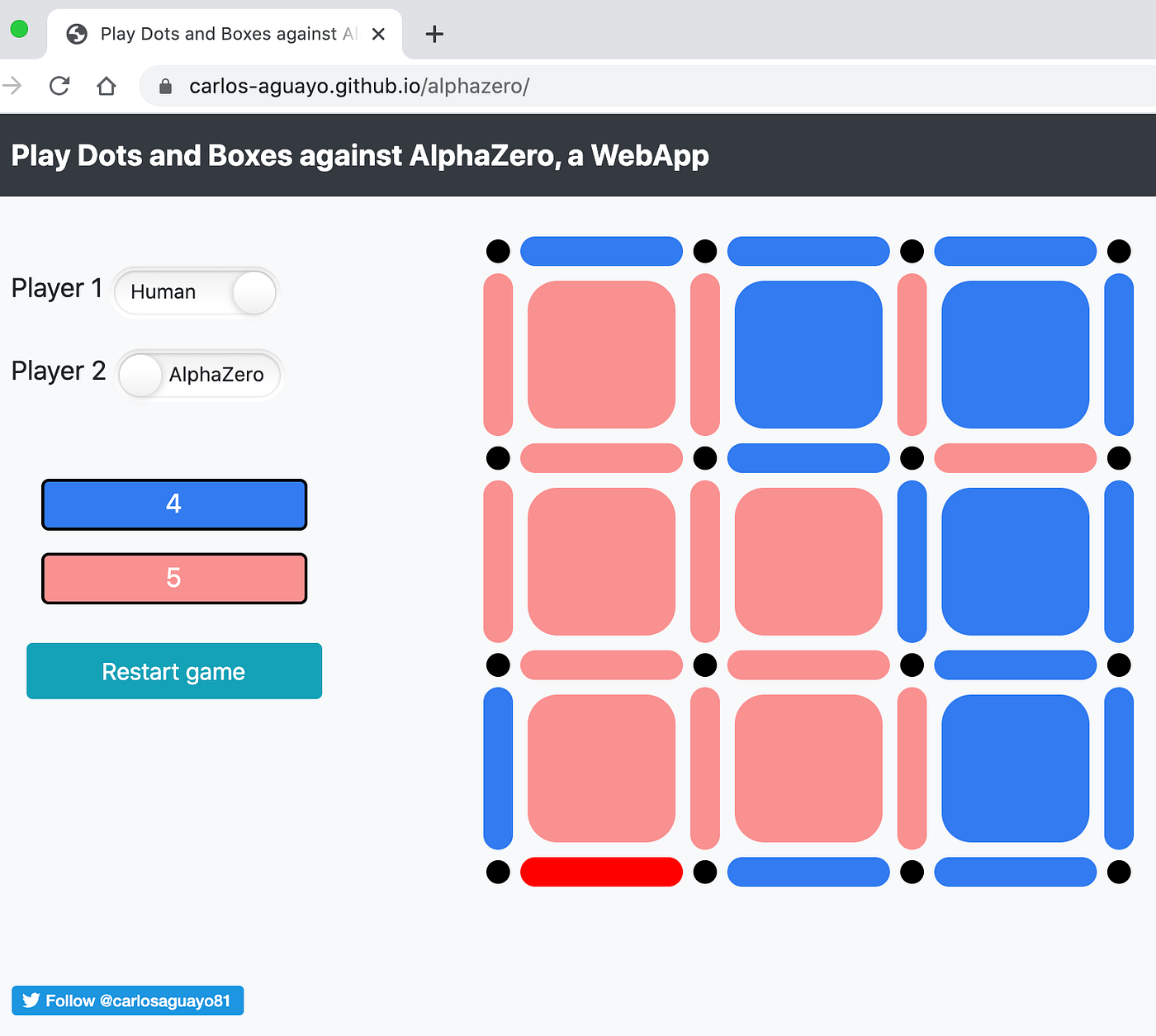
In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.

RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari

UC Berkeley Reward-Free RL Beats SOTA Reward-Based RL

PDF) Tensor Implementation of Monte-Carlo Tree Search for Model-Based Reinforcement Learning

PDF) OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments

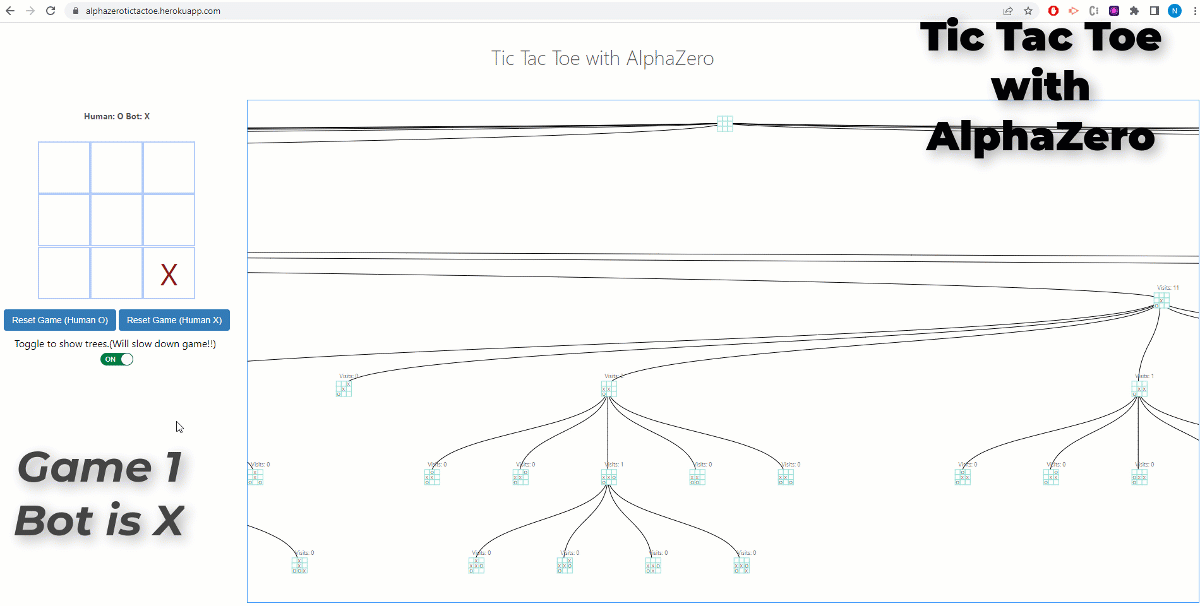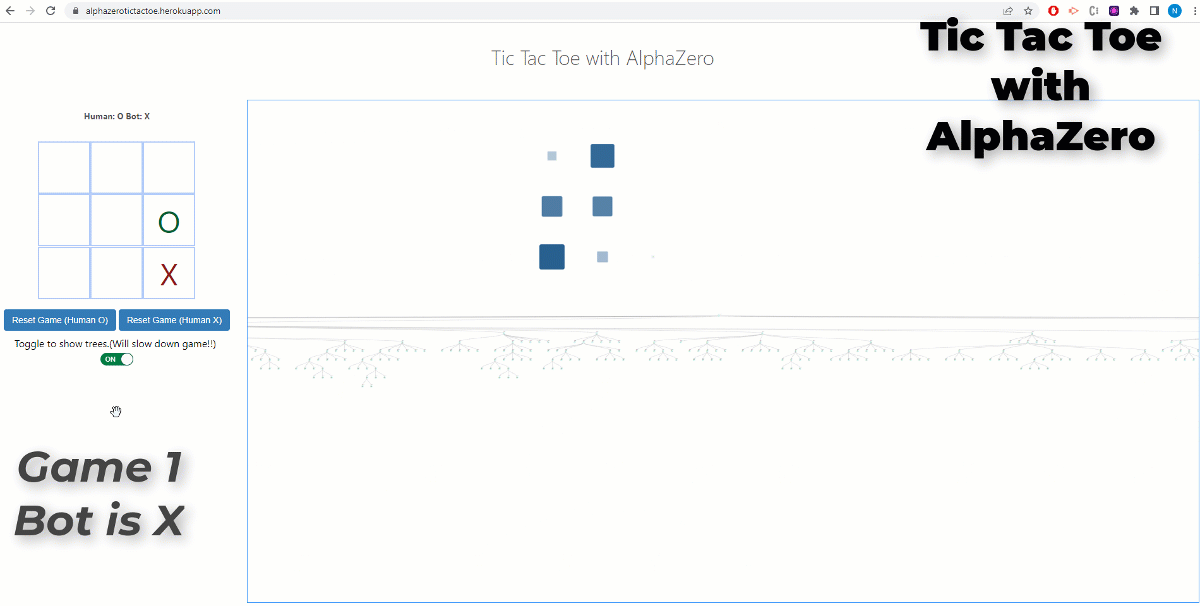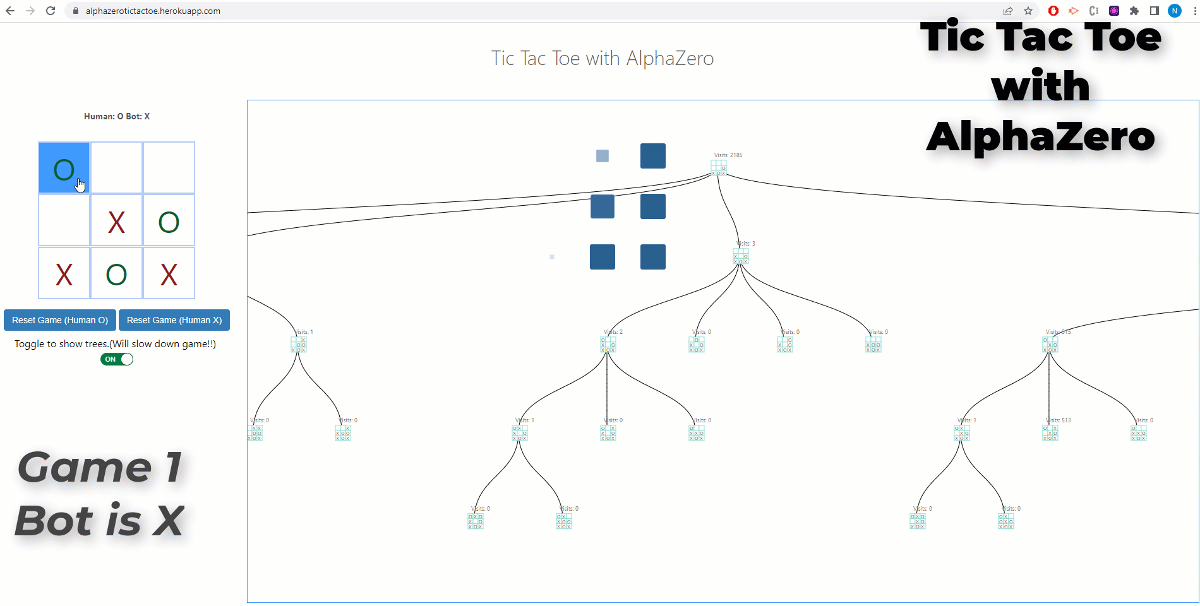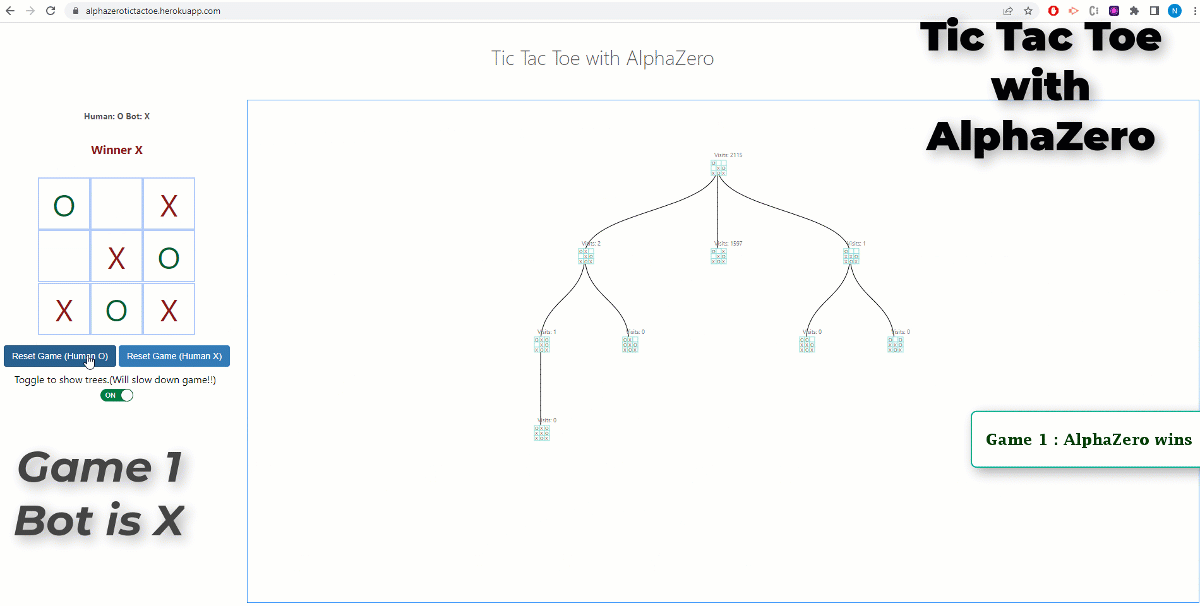
PDF) Alpha-T: Learning to Traverse over Graphs with An AlphaZero-inspired Self-Play Framework

RL Weekly 37: Observational Overfitting, Hindsight Credit Assignment, and Procedurally Generated Environment Suite
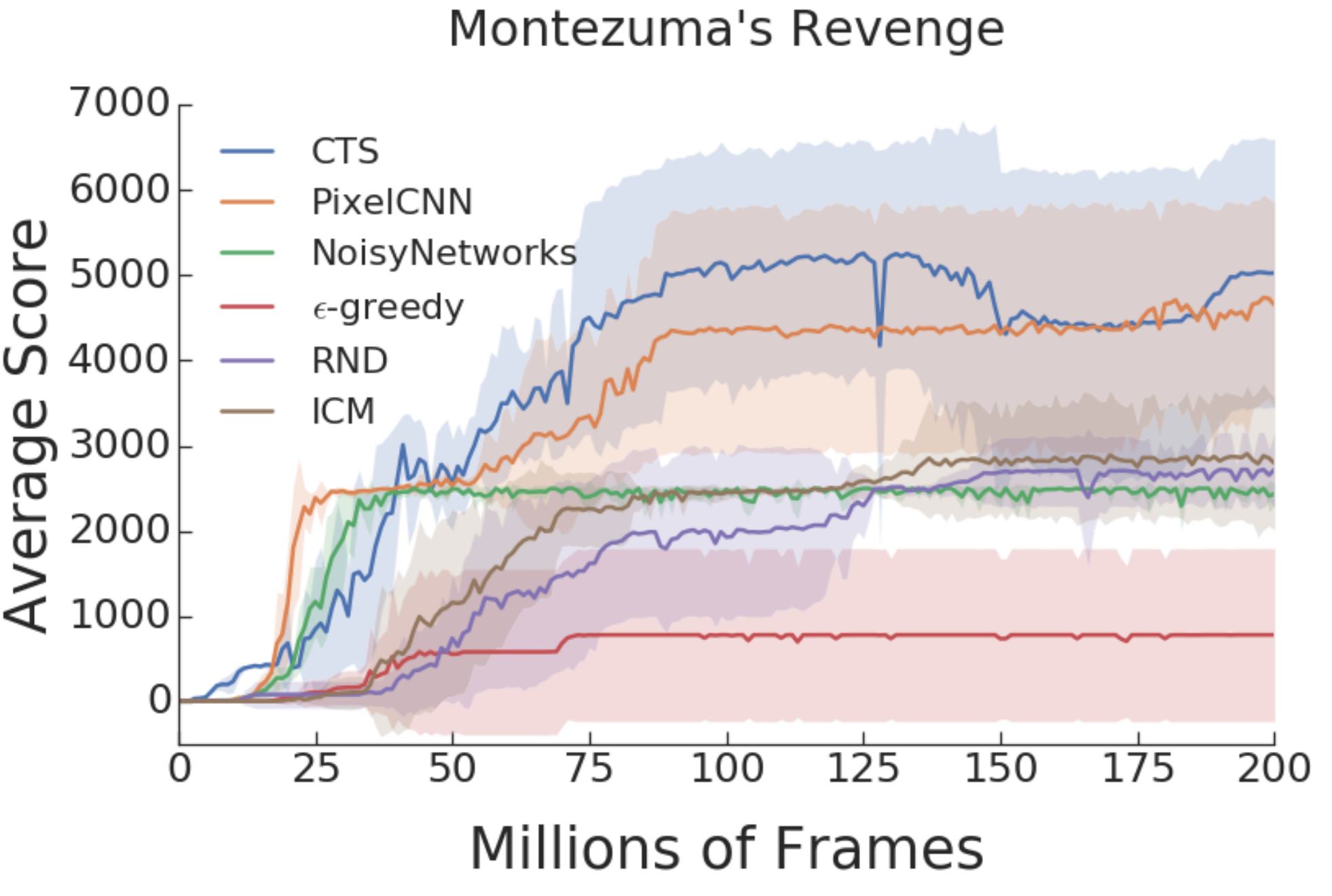
RL Weekly

Memory for Lean Reinforcement Learning.pdf

Atari 2600 Kangaroo Benchmark (Atari Games)

PDF) Mastering Atari Games with Limited Data

UC Berkeley Reward-Free RL Beats SOTA Reward-Based RL
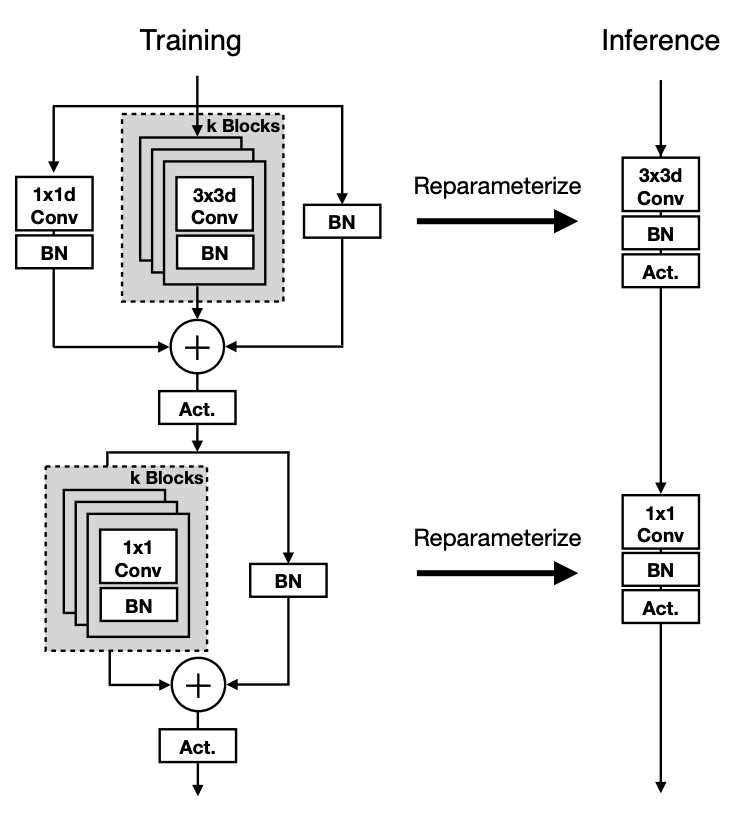
Aman's AI Journal • Papers List
State of AI Report 2023 - Air Street Capital
Memory-based Reinforcement Learning
Aman's AI Journal • Papers List
de
por adulto (o preço varia de acordo com o tamanho do grupo)